AMLab Papers at NeurIPS 2023
|
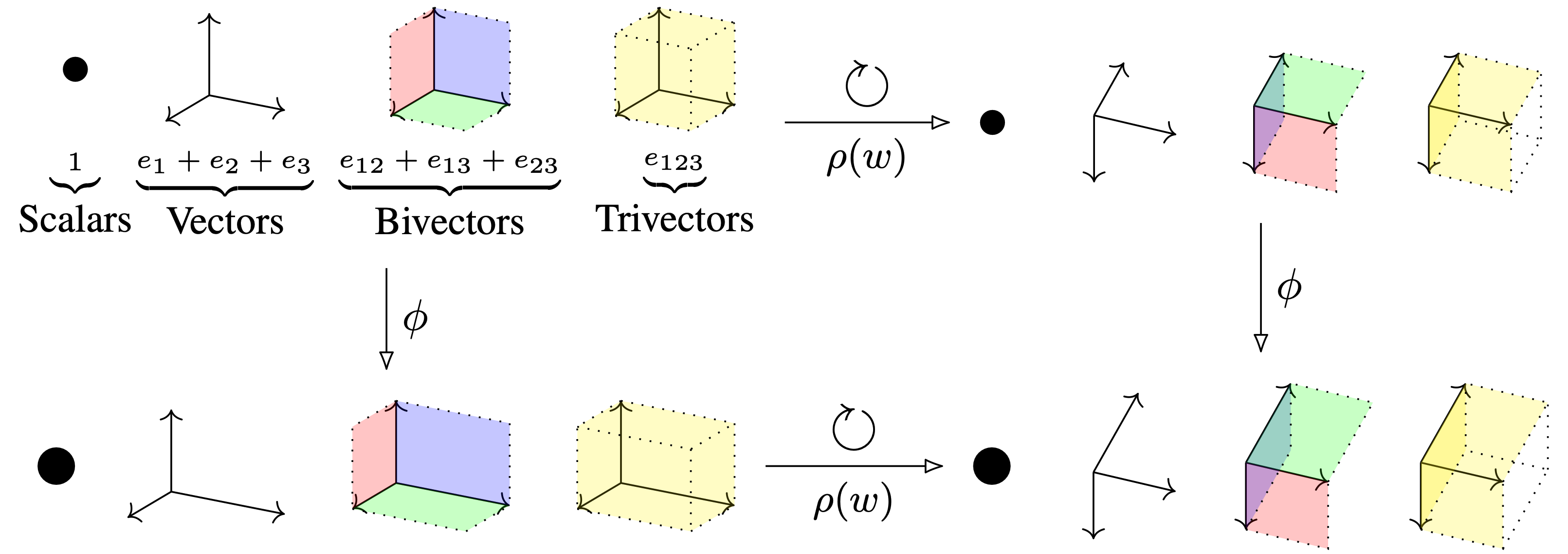
Clifford Group Equivariant Neural Networks David Ruhe, Johannes Brandstetter, Patrick Forré Conference paper · PDF · GitHub repo Abstract: We introduce Clifford Group Equivariant Neural Networks: a novel approach for constructing O(n)- and E(n)-equivariant models. We identify and study the Clifford group: a subgroup inside the Clifford algebra tailored to achieve several favorable properties. Primarily, the group's action forms an orthogonal automorphism that extends beyond the typical vector space to the entire Clifford algebra while respecting the multivector grading. This leads to several non-equivalent subrepresentations corresponding to the multivector decomposition. Furthermore, we prove that the action respects not just the vector space structure of the Clifford algebra but also its multiplicative structure, i.e., the geometric product. These findings imply that every polynomial in multivectors, including their grade projections, constitutes an equivariant map with respect to the Clifford group, allowing us to parameterize equivariant neural network layers. An advantage worth mentioning is that we obtain expressive layers that can elegantly generalize to inner-product spaces of any dimension. We demonstrate, notably from a single core implementation, state-of-the-art performance on several distinct tasks, including a three-dimensional N-body experiment, a four-dimensional Lorentz-equivariant high-energy physics experiment, and a five-dimensional convex hull experiment. #GeometricAlgebra #Equivariance #RepresentationTheory |
 Oral Presentation
Oral Presentation
|
|
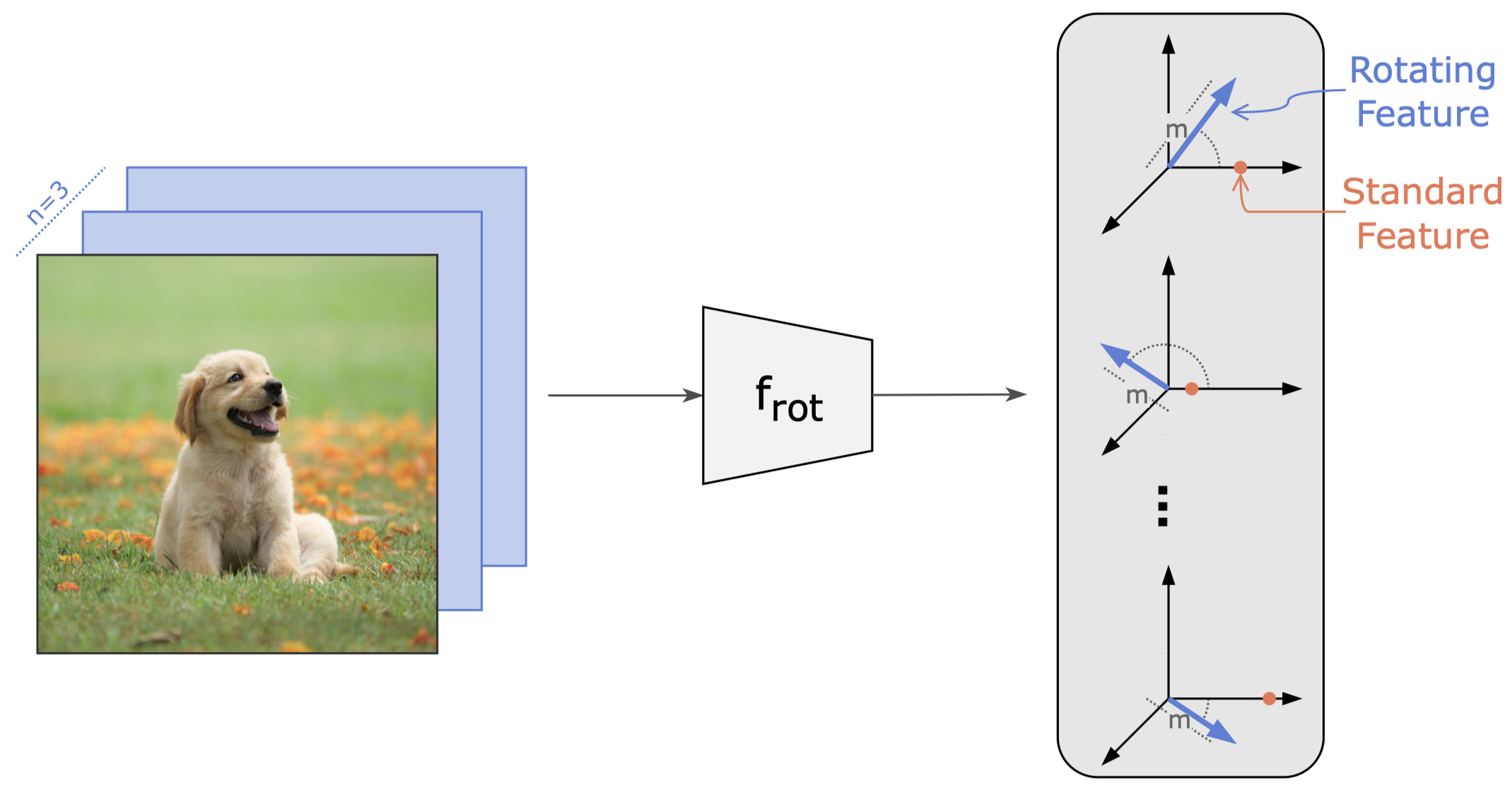
Rotating Features for Object Discovery Sindy Löwe, Phillip Lippe, Francesco Locatello, Max Welling Paper · PDF · GitHub repo Abstract: The binding problem in human cognition, concerning how the brain represents and connects objects within a fixed network of neural connections, remains a subject of intense debate. Most machine learning efforts addressing this issue in an unsupervised setting have focused on slot-based methods, which may be limiting due to their discrete nature and difficulty to express uncertainty. Recently, the Complex AutoEncoder was proposed as an alternative that learns continuous and distributed object-centric representations. However, it is only applicable to simple toy data. In this paper, we present Rotating Features, a generalization of complex-valued features to higher dimensions, and a new evaluation procedure for extracting objects from distributed representations. Additionally, we show the applicability of our approach to pre-trained features. Together, these advancements enable us to scale distributed object-centric representations from simple toy to real-world data. We believe this work advances a new paradigm for addressing the binding problem in machine learning and has the potential to inspire further innovation in the field. #ObjectDiscovery #RepresentationLearning #ComplexAutoEncoder |
 Oral Presentation
Oral Presentation
|
|
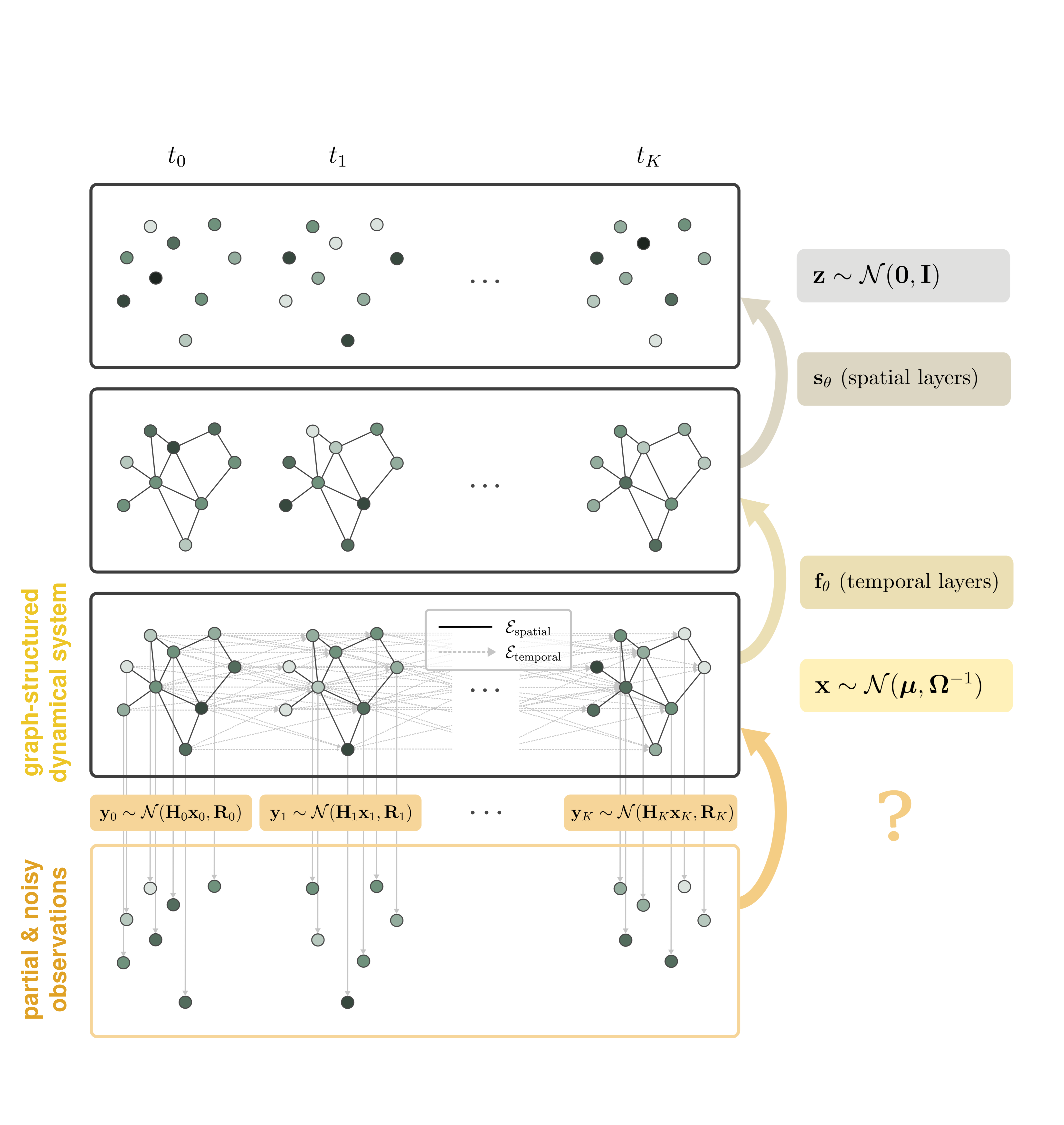
Deep Gaussian Markov Random Fields for graph-structured dynamical systems Fiona Lippert, Bart Kranstauber, E. Emiel van Loon, Patrick Forré Conference paper · PDF Abstract: Probabilistic inference in high-dimensional state-space models is computationally challenging. For many spatiotemporal systems, however, prior knowledge about the dependency structure of state variables is available. We leverage this structure to develop a computationally efficient approach to state estimation and learning in graph-structured state-space models with (partially) unknown dynamics and limited historical data. Building on recent methods that combine ideas from deep learning with principled inference in Gaussian Markov random fields (GMRF), we reformulate graph-structured state-space models as Deep GMRFs defined by simple spatial and temporal graph layers. This results in a flexible spatiotemporal prior that can be learned efficiently from a single time sequence via variational inference. Under linear Gaussian assumptions, we retain a closed-form posterior, which can be sampled efficiently using the conjugate gradient method, scaling favourably compared to classical Kalman filter based approaches. #GaussianMarkovRandomFields #SpatiotemporalModels #VariationalInference |
|
|
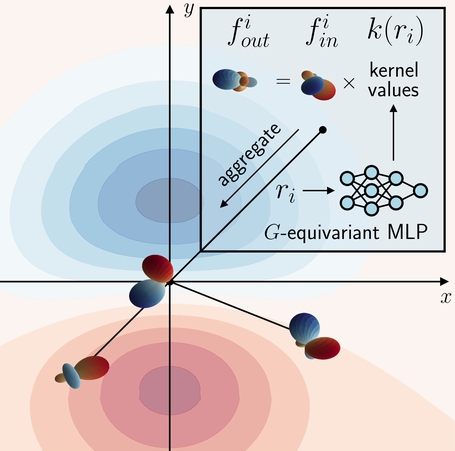
Implicit Convolutional Kernels for Steerable CNNs Maksim Zhdanov, Nico Hoffmann, Gabriele Cesa Conference paper · PDF · GitHub repo Abstract: Steerable convolutional neural networks (CNNs) provide a general framework for building neural networks equivariant to translations and other transformations belonging to an origin-preserving group \(G\), such as reflections and rotations. They rely on standard convolutions with \(G\)-steerable kernels obtained by analytically solving the group-specific equivariance constraint imposed onto the kernel space. As the solution is tailored to a particular group \(G\), the implementation of a kernel basis does not generalize to other symmetry transformations, which complicates the development of general group equivariant models. We propose using implicit neural representation via multi-layer perceptrons (MLPs) to parameterize \(G\)-steerable kernels. The resulting framework offers a simple and flexible way to implement Steerable CNNs and generalizes to any group \(G\) for which a \(G\)-equivariant MLP can be built. We prove the effectiveness of our method on multiple tasks, including N-body simulations, point cloud classification, and molecular property prediction. #SteerableCNNs #Equivariance #MolecularSimulations |
|
|
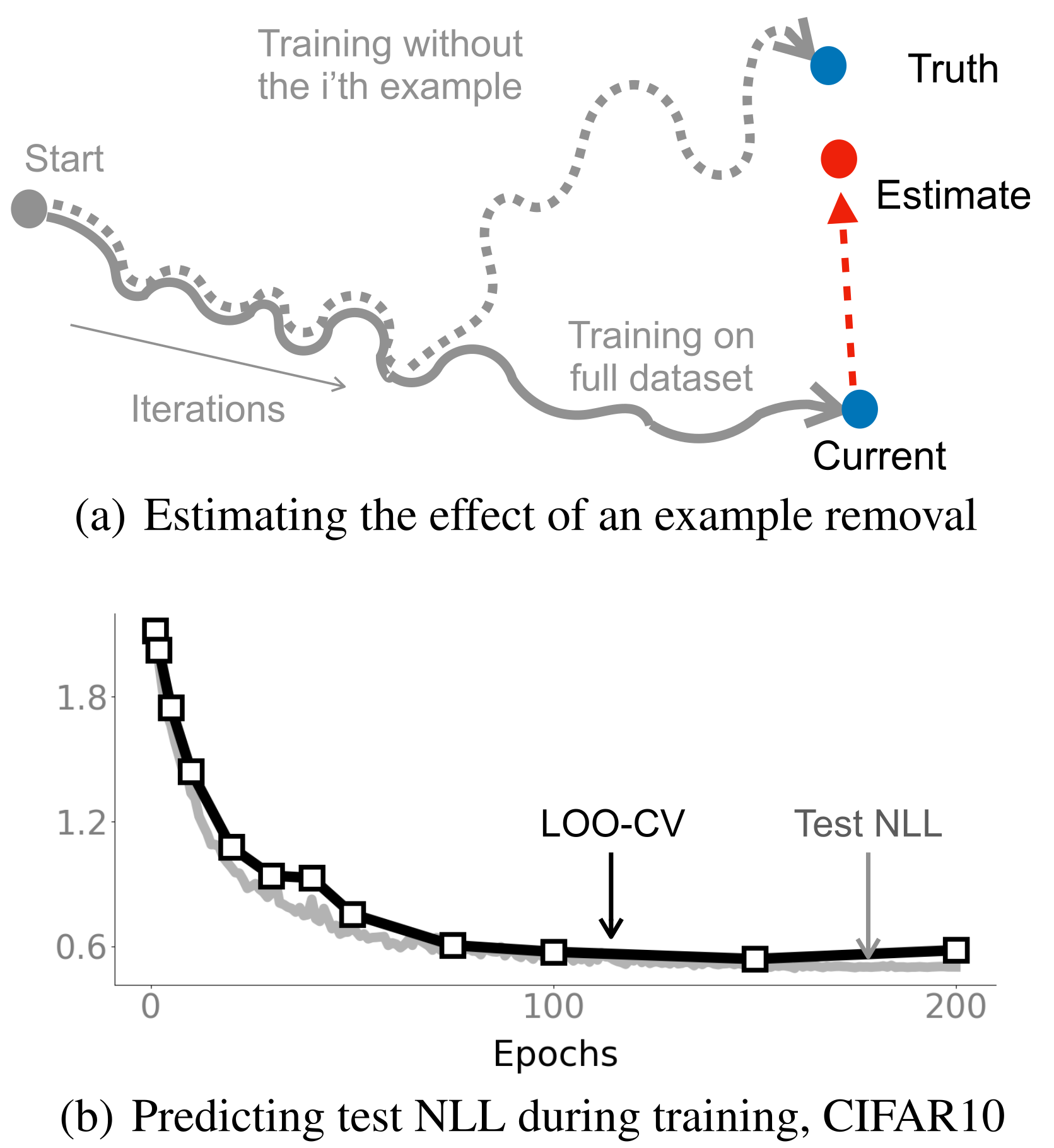
The Memory-Perturbation Equation: Understanding Model's Sensitivity to Data Peter Nickl, Lu Xu*, Dharmesh Tailor*, Thomas Möllenhoff, Emtiyaz Khan (*=equal contribution) Conference paper · PDF · GitHub repo Abstract: Understanding model's sensitivity to its training data is crucial but can also be challenging and costly, especially during training. To simplify such issues, we present the Memory-Perturbation Equation (MPE) which relates model's sensitivity to perturbation in its training data. Derived using Bayesian principles, the MPE unifies existing sensitivity measures, generalizes them to a wide-variety of models and algorithms, and unravels useful properties regarding sensitivities. Our empirical results show that sensitivity estimates obtained during training can be used to faithfully predict generalization on unseen test data. The proposed equation is expected to be useful for future research on robust and adaptive learning. #MemoryPerturbationEquation #Sensitivity #Generalization |
|
|
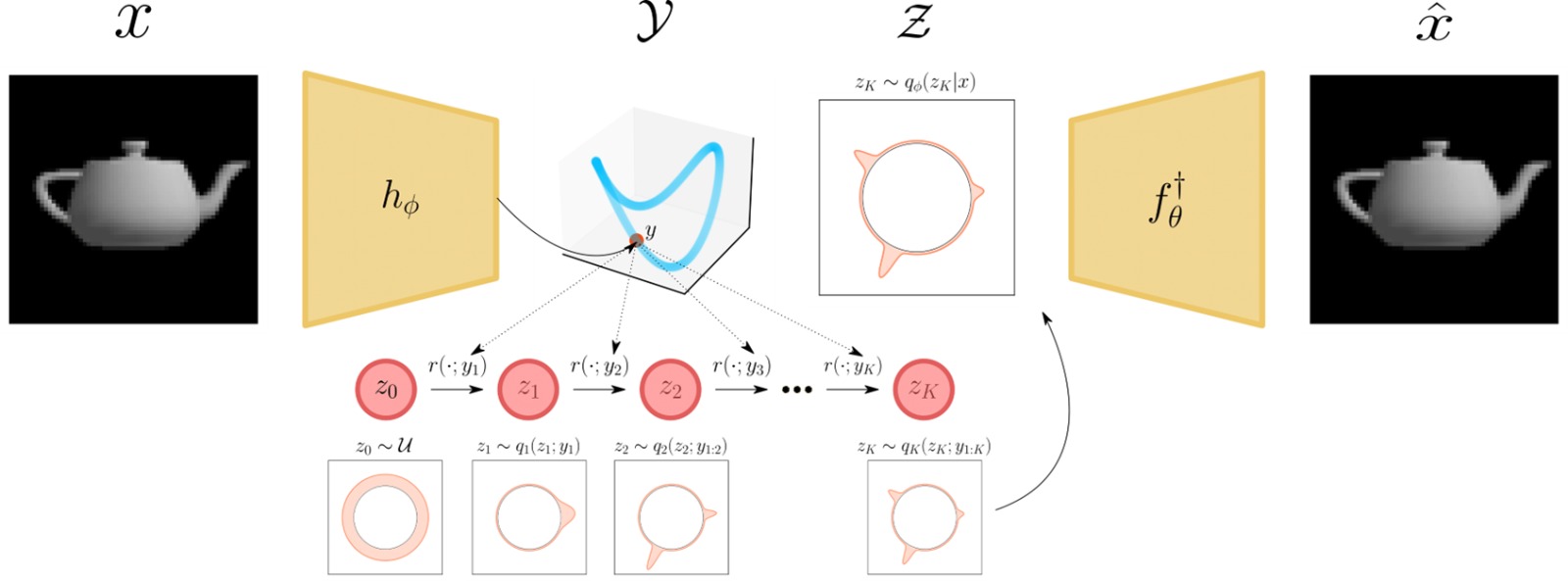
Topological Obstructions and How to Avoid Them Babak Esmaeili, Robin Walters, Heiko Zimmermann, Jan-Willem van de Meent Conference paper · PDF · Abstract: Incorporating geometric inductive biases into models can aid interpretability and generalization, but encoding to a specific geometric structure can be challenging due to the imposed topological constraints. In this paper, we theoretically and empirically characterize obstructions to training encoders with geometric latent spaces. We show that local optima can arise due to singularities (e.g. self-intersection) or due to an incorrect degree or winding number. We then discuss how normalizing flows can potentially circumvent these obstructions by defining multimodal variational distributions. Inspired by this observation, we propose a new flow-based model that maps data points to multimodal distributions over geometric spaces and empirically evaluate our model on 2 domains. We observe improved stability during training and a higher chance of converging to a homeomorphic encoder. #GeometricInductiveBiases #DataTopology #NormalizingFlows |
|
|
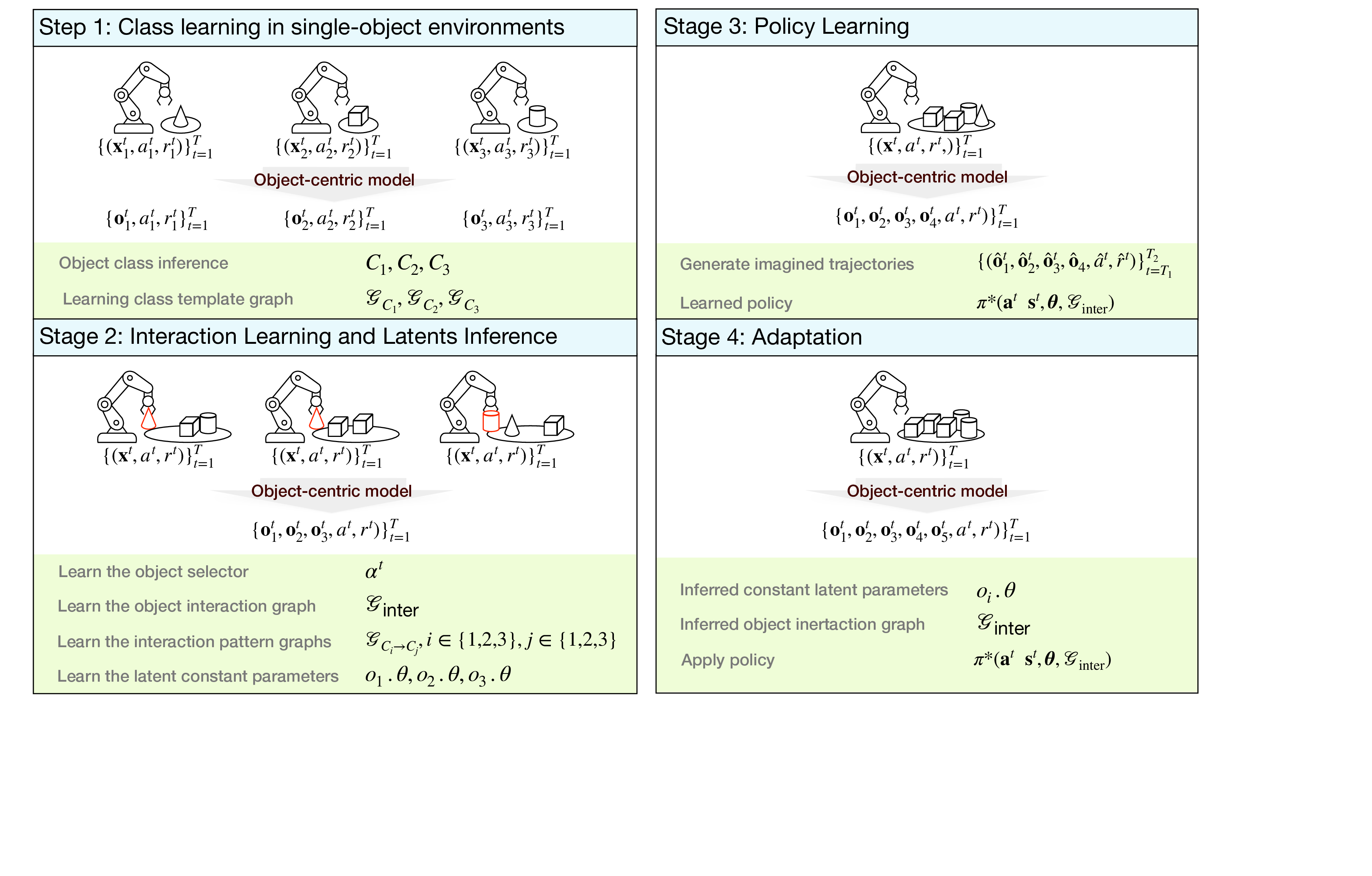
Learning Dynamic Attribute-factored World Models for Efficient Multi-object Reinforcement Learning Fan Feng, Sara Magliacane Paper · PDF · Abstract: In many reinforcement learning tasks, the agent has to learn to interact with many objects of different types and generalize to unseen combinations and numbers of objects. Often a task is a composition of previously learned tasks (e.g. block stacking). These are examples of compositional generalization, in which we compose object-centric representations to solve complex tasks. Recent works have shown the benefits of object-factored representations and hierarchical abstractions for improving sample efficiency in these settings. In this paper, we introduce the Dynamic Attribute FacTored RL (DAFT-RL) framework. In DAFT-RL, we leverage object-centric representation learning to extract objects from visual inputs, classify them in classes, and infer their latent parameters. For each class of object, we learn a class template graph that describes the dynamics and reward of an object of this class factorized according to its attributes. We also learn an interaction pattern graph that describes how objects of different classes interact with each other at the attribute level. Through these graphs and a dynamic interaction graph that models the interactions between objects, we learn a policy that can then be directly applied in a new environment by just estimating the interactions and latent parameters. We evaluate DAFT-RL in three benchmark datasets and show our framework outperforms the state-of-the-art in generalizing across unseen objects with varying attributes and latent parameters, as well as in the composition of previously learned tasks. #ReinforcementLearning #ObjectCentricRepresentations |
|
|
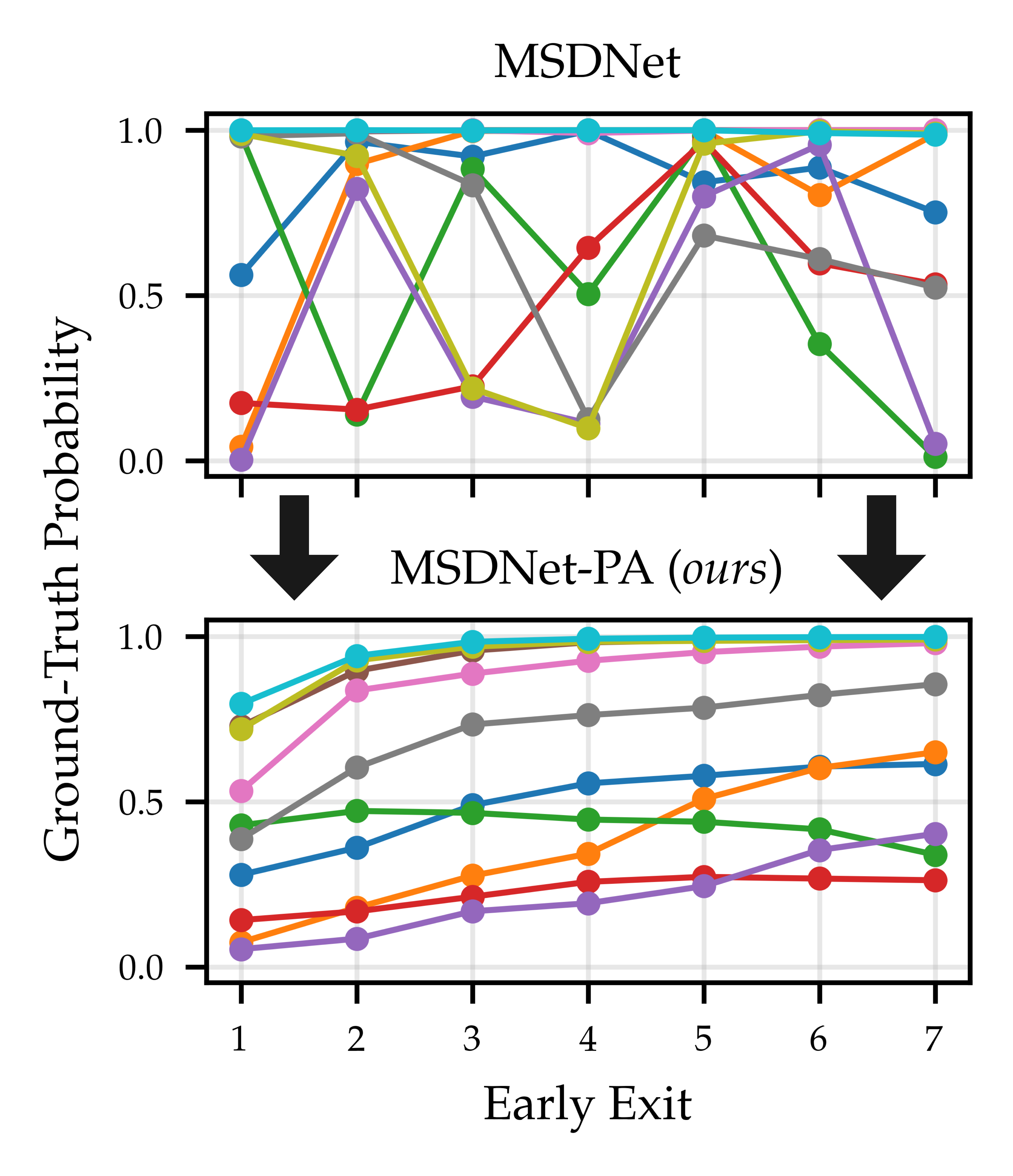
Towards Anytime Classification in Early-Exit Architectures by Enforcing Conditional Monotonicity Metod Jazbec, James Urquhart Allingham, Dan Zhang, Eric Nalisnick Paper · GitHub repo Abstract: Modern predictive models are often deployed to environments in which computational budgets are dynamic. Anytime algorithms are well-suited to such environments as, at any point during computation, they can output a prediction whose quality is a function of computation time. Early-exit neural networks have garnered attention in the context of anytime computation due to their capability to provide intermediate predictions at various stages throughout the network. However, we demonstrate that current early-exit networks are not directly applicable to anytime settings, as the quality of predictions for individual data points is not guaranteed to improve with longer computation. To address this shortcoming, we propose an elegant post-hoc modification, based on the Product-of-Experts, that encourages an early-exit network to become gradually confident. This gives our deep models the property of conditional monotonicity in the prediction quality -- an essential stepping stone towards truly anytime predictive modeling using early-exit architectures. Our empirical results on standard image-classification tasks demonstrate that such behaviors can be achieved while preserving competitive accuracy on average. #AnytimeClassification #EarlyExitNetworks #ImageClassification |
|
Workshops
|
Switching policies for solving inverse problems Tim Bakker, Fabio Valerio Massoli, Thomas Hehn, Tribhuvanesh Orekondy, Arash Behboodi Conference paper · PDF · Abstract: In recent years, inverse problems for black-box simulators have enjoyed increased focus of the machine learning community due to their prevalence in science and engineering domains. Such simulators describe a forward process \(f: (\psi, x) \rightarrow y\). Here the intent is to optimise simulator parameters \(\psi\) to minimise some observation loss on \(y\), under some input distribution on \(x\). Optimisation of such objectives is often challenging, since it is not trivial to estimate simulator gradients accurately. In settings where multiple related inverse problems need to be solved simultaneously, from-scratch/ab-initio optimisation of each may be infeasible if the forward model is expensive to evaluate. In this paper, we propose a novel method for solving such families of inverse problems with reinforcement learning. We train a policy to guide the optimisation by selecting between gradients estimated numerically from the simulator and gradients estimated from a pre-trained surrogate model. After training the surrogate and the policy, downstream inverse problem optimisations require 10%-70% fewer simulator evaluations. Moreover, the policy does successful optimisations on functions where using just simulator gradient estimates fails. #InverseProblems #ReinforcementLearning |
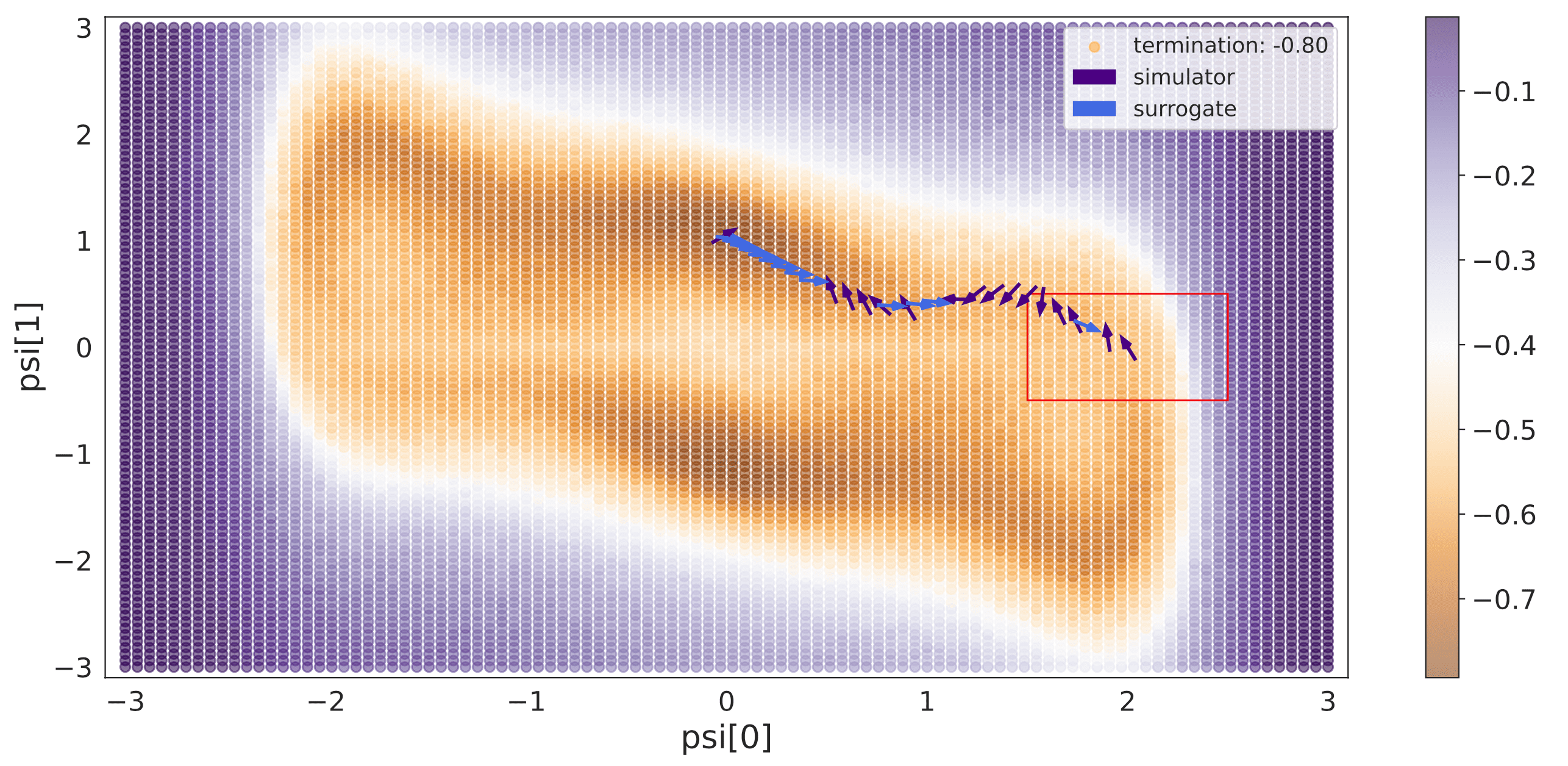
|
|
Active Learning Policies for Solving Inverse Problems Tim Bakker, Thomas Hehn, Tribhuvanesh Orekondy, Arash Behboodi, Fabio Valerio Massoli Conference paper Abstract: In recent years, solving inverse problems for black-box simulators has become a point of focus for the machine learning community due to their ubiquity in science and engineering scenarios. In such settings, the simulator describes a forward process \(f: (\psi, x) \rightarrow y\) from simulator parameters \(\psi\) and input data \(x\) to observations \(y\), and the goal of the inverse problem is to optimise \(\psi\) to minimise some observation loss. Simulator gradients are often unavailable or prohibitively expensive to obtain, making optimisation of these simulators particularly challenging. Moreover, in many applications, the goal is to solve a family of related inverse problems. Thus, starting optimisation ab-initio/from-scratch may be infeasible if the forward model is expensive to evaluate. In this paper, we propose a novel method for solving classes of similar inverse problems. We learn an active learning policy that guides the training of a surrogate and use the gradients of this surrogate to optimise the simulator parameters with gradient descent. After training the policy, downstream inverse problem optimisations require up to 90\% fewer forward model evaluations than the baseline. #InverseProblems #ActiveLearning |
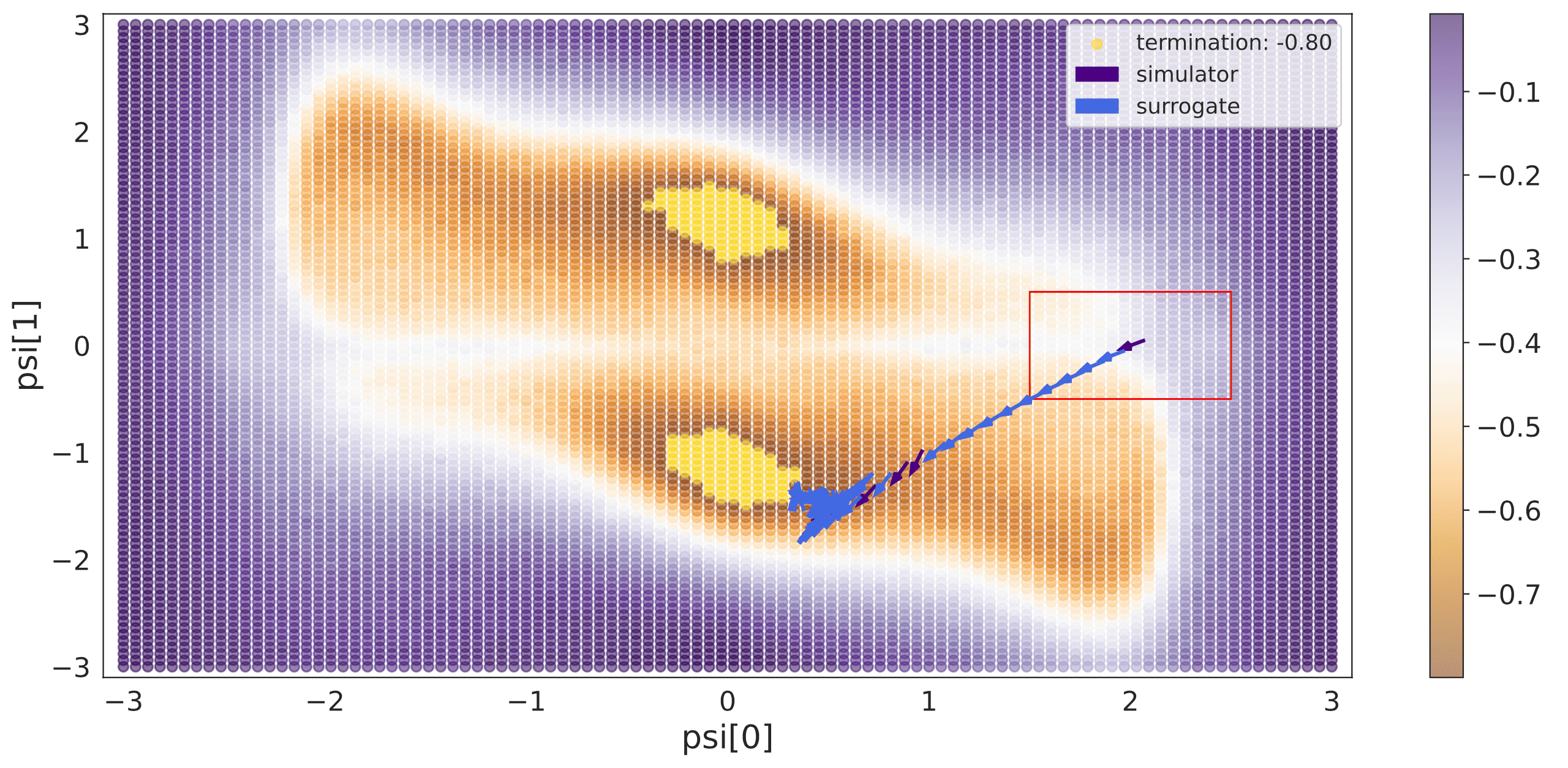
|
|
Designing Long-term Group Fair Policies in Dynamical Systems Miriam Rateike, Isabel Valera, Patrick Forré Paper · PDF · Abstract: This paper proposes a novel framework for achieving long-term group fairness in dynamical systems. The framework aims to identify a time-independent policy that ensures convergence to a fair stationary state, regardless of the initial data distribution. By modeling system dynamics with a time-homogeneous Markov chain and leveraging the Markov chain convergence theorem, the paper provides examples of various long-term fair states and demonstrates how the approach can evaluate the impact of different long-term targets on group-conditional population distribution over time. #LongTermFairness #DynamicalSystems #MarkovChains |
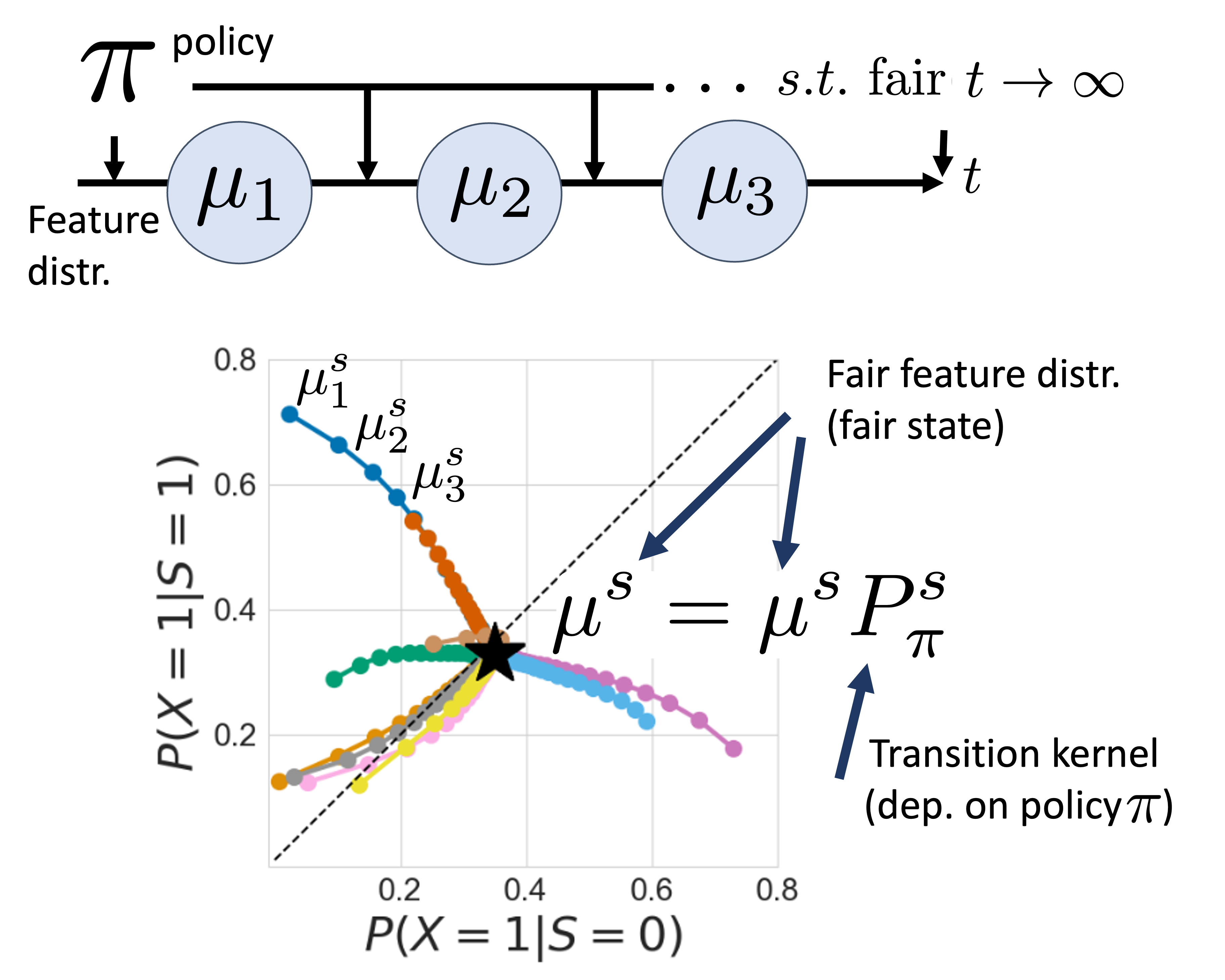 Oral Presentation
Oral Presentation
|